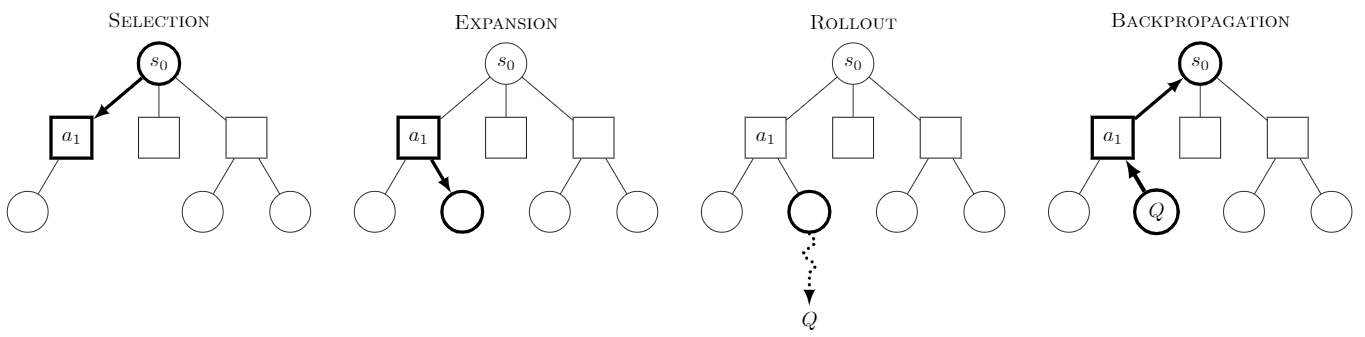
The mention of Q* has excited a good number of people. Perhaps, this is with good reason. If the rumours are to be believed, then the inclusion of successfully applied techniques such as the Monte-Carlo Tree Search could mean our collective excitement isn’t in vain.
It’s possible OpenAI are about to shock the world just as Deepmind shocked us all with their 4-1 victory over Lee Sedol. A moment that catches the world’s breath as we are forced to contemplate a world where computers can beat us at our own game.
The techniques pioneered by Deepmind and now purportedly adopted by OpenAI may lead to a ChatGPT-6.5 Turbo that can effectively breakdown a broad range of complex tasks into more manageable chunks. It’s possible that a large proportion of us, now tapping away at our keyboards and flourishing our ‘uniquely human’ capabilities, may be able to put our feet up a little sooner than anticipated.
Or perhaps it’s just a rumour and we should all get back to work.