Introduction
In the high-stakes, high-risk artificial intelligence (AI) landscape, ‘guardrail’ development offers businesses a path to responsible, risk-mitigated AI deployment. Businesses seeking to harness the capabilities of generative AI, namely Large Language Models (LLMs) like ChatGPT (a closed-source model) or Llama 2.0 (a comparable open-source model), invariably stumble upon issues with some of its behaviours.
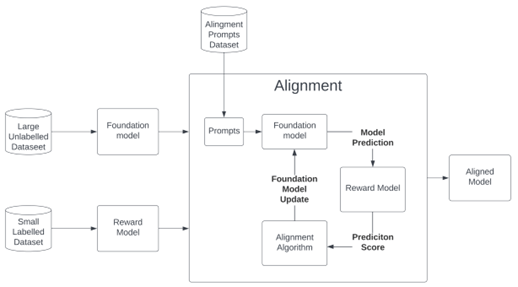
Naturally, organisations must retain a high degree of control over the content that LLMs produce. Aligning LLM behaviours with organisational tone and goals, its choice of language, its perceived ethical stances, and opinions in general, is achieved via a process called ‘fine-tuning’.
There is also a national security threat. Imagine a password of sorts that criminals could share, enabling them to unlock existing opensource LLMs, to unlock a criminal instruction manual!
The UK Government has recognised the need to support industry in the development of safe, secure and responsible AI development. They are coordinating researchers and politicians around various AI Safety issues, to secure a leadership role for the UK on the global stage. The alignment of LLMs has been identified as one of the major challenges in AI development, and so Advai are conducting some cutting edge technical research in this area.
In this article, we’d like to introduce you to some of the challenges surrounding LLM guardrail development and overview the method of ‘fine-tuning’ that seeks to control LLMs.